Building a Strong Data Foundation to Get Machine Learning and Automation Right
Benchling is a life sciences R&D software platform. Our clients include 12 of the top 25 pharmaceutical companies, emerging biotechs, and companies across a variety of other industries. Our goal is to improve their scientists’ productivity with modern software.
Given the world that artificial intelligence promises, our customers are really interested in how advanced data analysis and machine learning techniques can up-level their R&D efforts: from discovery, to lead optimization, process development, pre-clinical, and even IND filings. There’s no lack of enthusiasm to leverage these tools, so how do we get to that world?
Machine Learning: Expectations vs. Reality
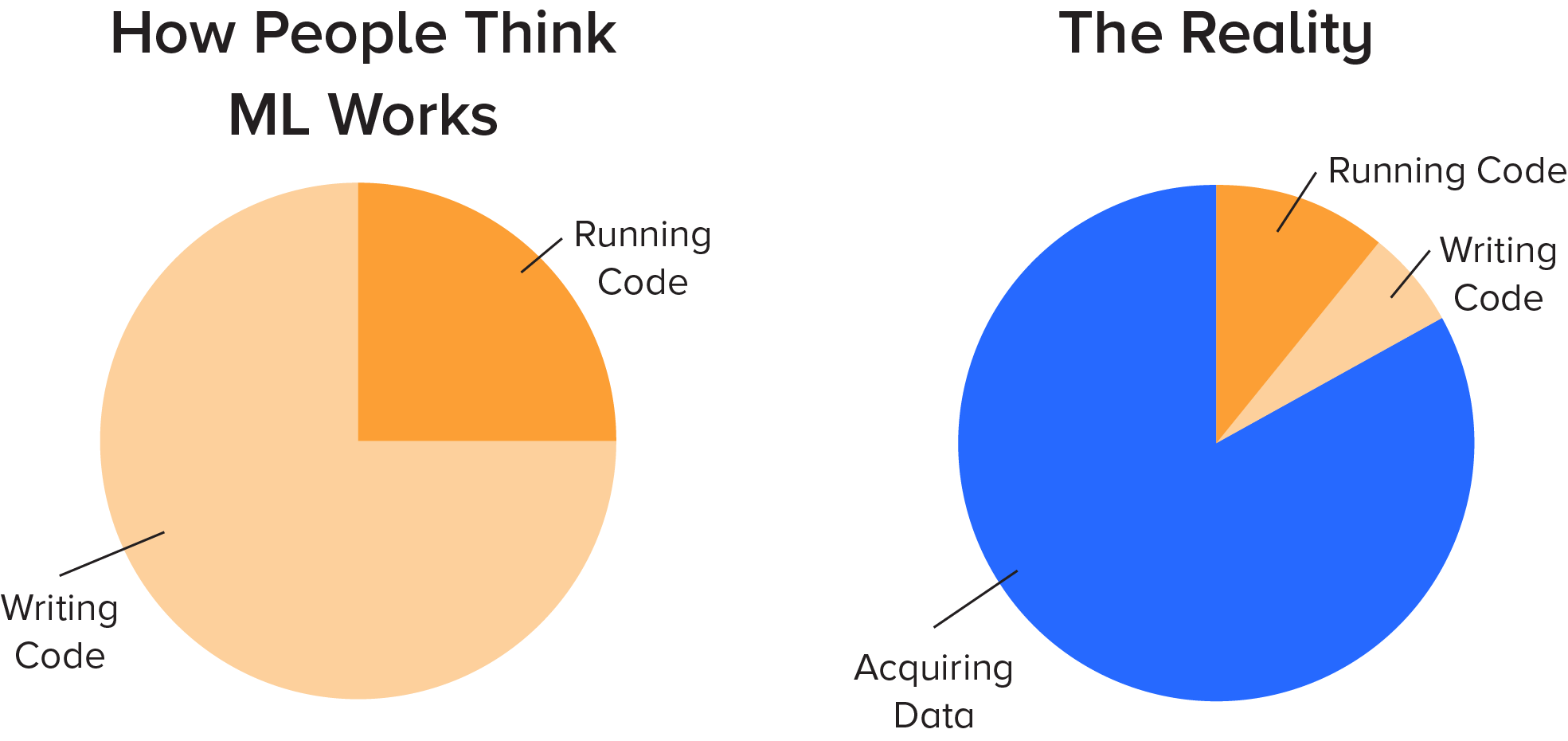
When applying AI, people often think that the majority of their time will be spent writing complex algorithms to find previously unknown insights. The reality is that the majority of the time will be spent acquiring and cleaning data.
In 2018, the CEO of Novartis declared that Novartis would become a data science company. A year later, he discussed the challenges of powering their R&D with data science and the need for good, clean data.
So what’s the solution? If all the work scientists do is captured in software, it ought to be easier to analyze.
The first thing we’ve learned is the importance of having outstanding data to actually base your ML on. In our own shop, we’ve been working on a few big projects, and we’ve had to spend most of the time just cleaning the data sets before you can even run the algorithm. It’s taken us years just to clean the datasets. I think people underestimate how little clean data there is out there, and how hard it is to clean and link the data.—Vasant Narasimhan, CEO of Novartis
The solution is software, but it’s not that simple
Many companies have embarked on a digitalization journey, convinced that their notebook entries, DNA and protein designs, samples used in experiments, and experimental conditions should all be tracked and stored in software. If we go down this path and digitalize everything scientists are doing, we should be well on our way to leveraging all those insights data science can provide.
However, there are challenges with this approach. First, your users are scientists, who are extremely well trained but not software specialists. Second, their workflows are complex, evolving, and in a deep domain area. It’s not easy to build high quality software in these conditions. We actually have an example of a similar industry that underwent a digital transformation with mixed results.
A cautionary tale of electronic medical records
We have a cautionary tale from our friends on the clinical side of the healthcare industry. Up until 10 years ago, healthcare delivery was primarily run off of pen and paper. This process was error prone, limited the ability to coordinate patient care, and the data wasn’t in a format that could be readily analyzed. The goal of digitalizing clinical workflows was a good one, but now clinicians are the most overeducated manual data entry workforce in the world. The government is even drafting proposals to ease the IT burden on clinicians. Doctors often don’t feel the day-to-day benefit of using electronic medical records (EMRs), which is leading to burnout and frustration among health care providers. We can’t repeat this mistake with scientists in life science R&D.
User-centric applications lead to high quality data
Where did electronic medical records go wrong? Too much emphasis was placed on the end goals of complete digitalization and billing, and not enough emphasis was placed on making doctors more productive along the way.
This probably sounds familiar to anyone who’s seen the state of software in life science R&D. When I was meeting with a leading technologist at a pharmaceutical company a few months ago, he jokingly said, “The best way to get compliance and adoption of tools that you introduce to scientists is to uninstall Excel from all of their computers.” It seemed a little bit extreme, but I saw where he was coming from. Excel is a very powerful and flexible tool, and it’s popular with scientists for a reason. If another system isn’t easy for them to use, if it doesn’t link data together, and if it doesn’t bring them immediate productivity, they’ll use Excel instead.
I don’t think the solution is to uninstall Excel; I think the solution is to build tools that bring scientists enough value such that they choose to use purpose-built software over Excel.
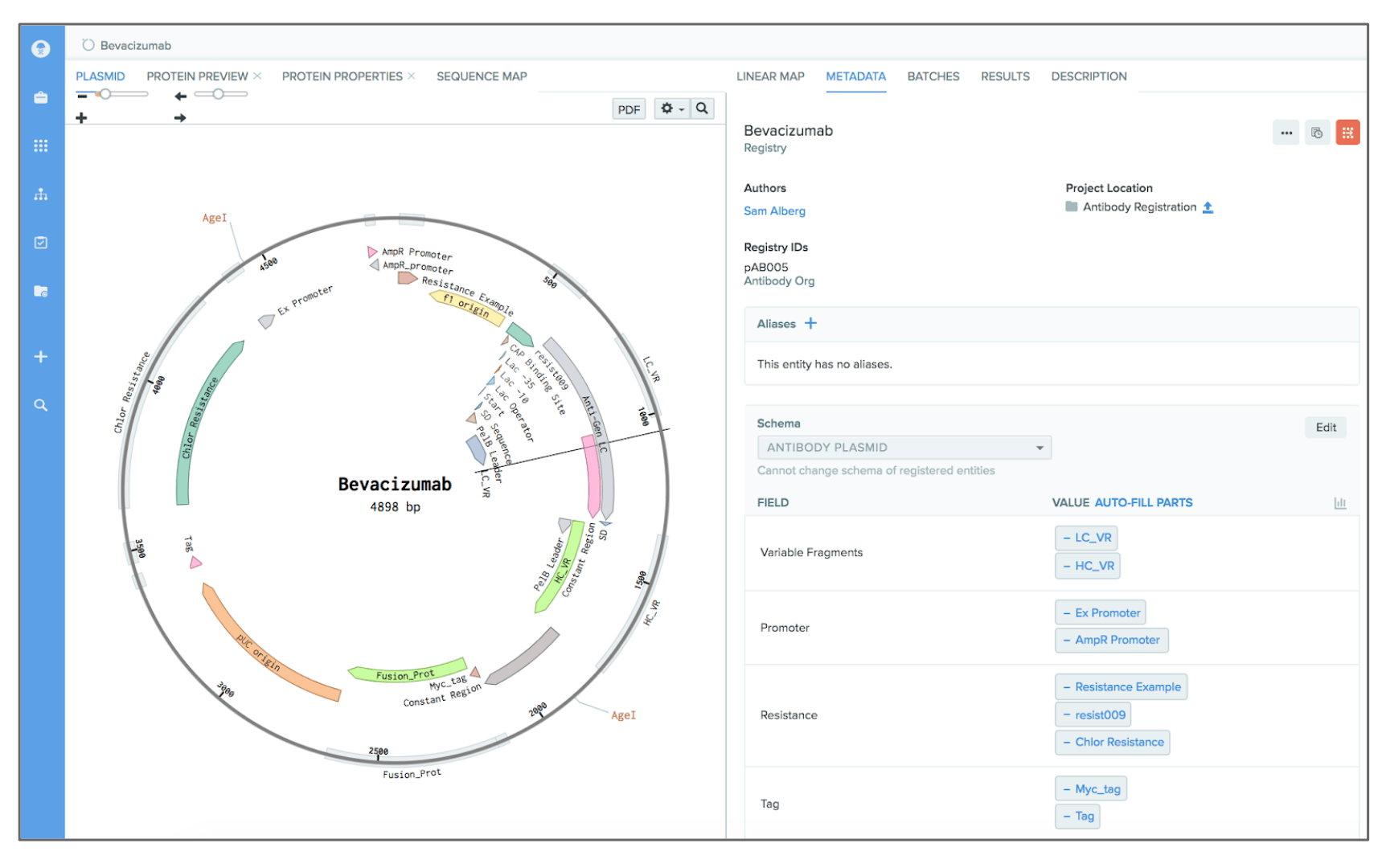
Software needs to accommodate the complexity of the data that scientists are producing, and it needs to do so with a flexible data structure.
Life science R&D data is highly complex and deserves purpose-built software
Why is this such a challenge in life sciences? Large molecule data is extremely complex. Let’s take a relatively simple example: with antibody engineering, you might start with an antibody, its target, and its binding affinity. But you also need the DNA sequences that encode for the antibody chains, the combination of plasmids used to express the antibody, growth conditions for cell lines to express the antibody, screening data, and so on. All of this needs to be modeled, stored, tracked, and analyzed, but most software isn’t equipped to deal with the complexity specific to large molecule R&D. Scientists will only use your software if it accommodates the complexity of the data they create and is flexible to change.
Life science R&D data needs to be centralized...
Specialized point solutions for each of your research and development teams can cause significant problems for teams doing data analysis. Each software has a different vendor, models its data differently, and instead of a “data lake” pooling the data together, you end up with a data swamp. Rather than analyzing data, your data science or bioinformatics team will be spending their time linking, reconciling, and cleaning data. Capturing data on a unified platform can dramatically reduce this burden.
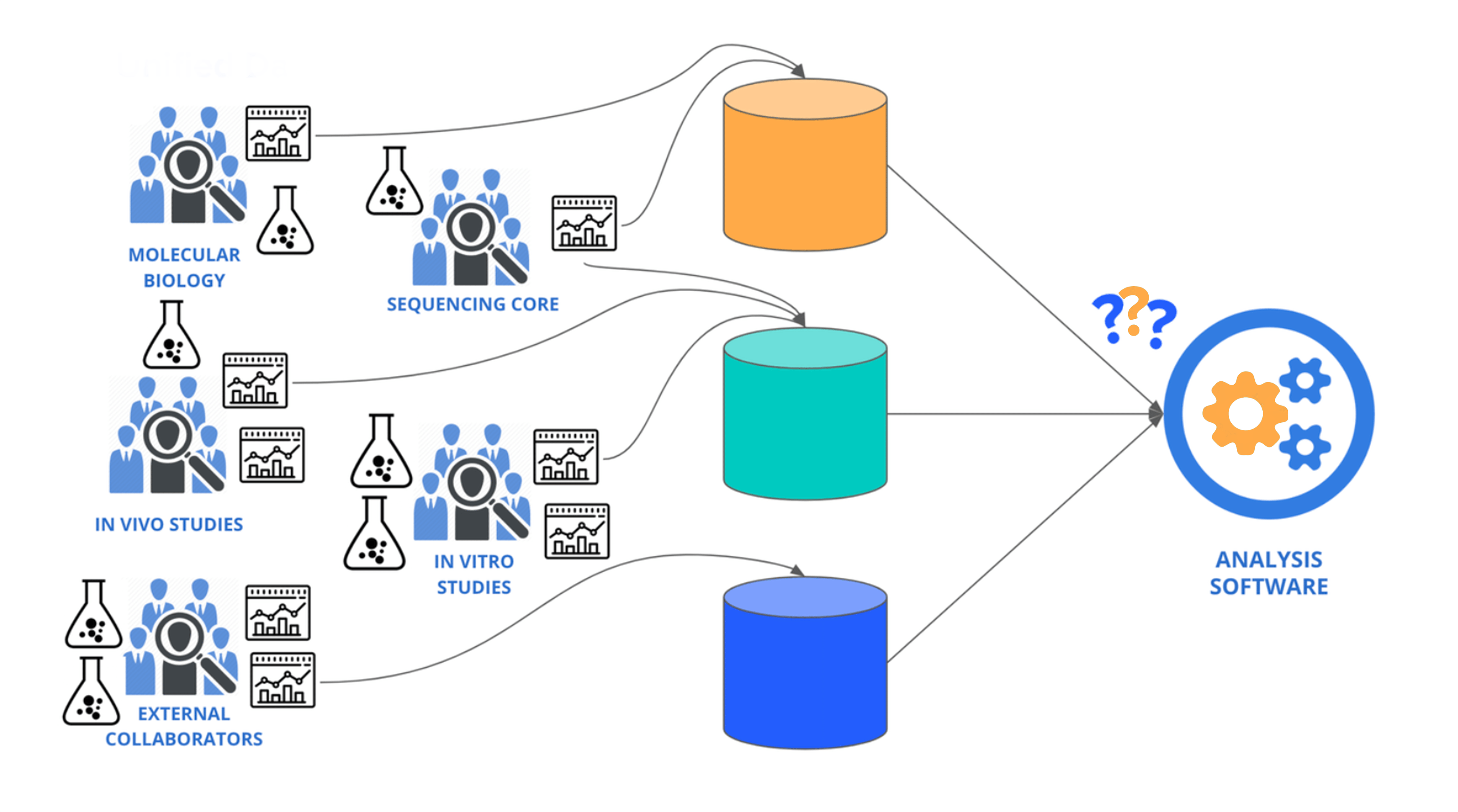
Centralizing and standardizing data across disparate teams is a crucial challenge for life science R&D organizations.
...on a flexible software platform
Another big challenge for software adoption in life science is that while a tool may be initially configured to represent a scientific workflow, that workflow constantly evolves. Scientists may need to test, for example, new versions of a protein purification process in order to improve the quality of the purified sample generated. Scientists will go where the data leads them, and it’s very important to have software that is adaptive to changes in experimental workflows. If the software doesn’t keep up with the science, the tools will become out of date and scientists will opt for unstructured notebook entries, Word documents, or pen and paper. Given the pace of the scientific process today, you need software to be able to change in days or weeks, not months.
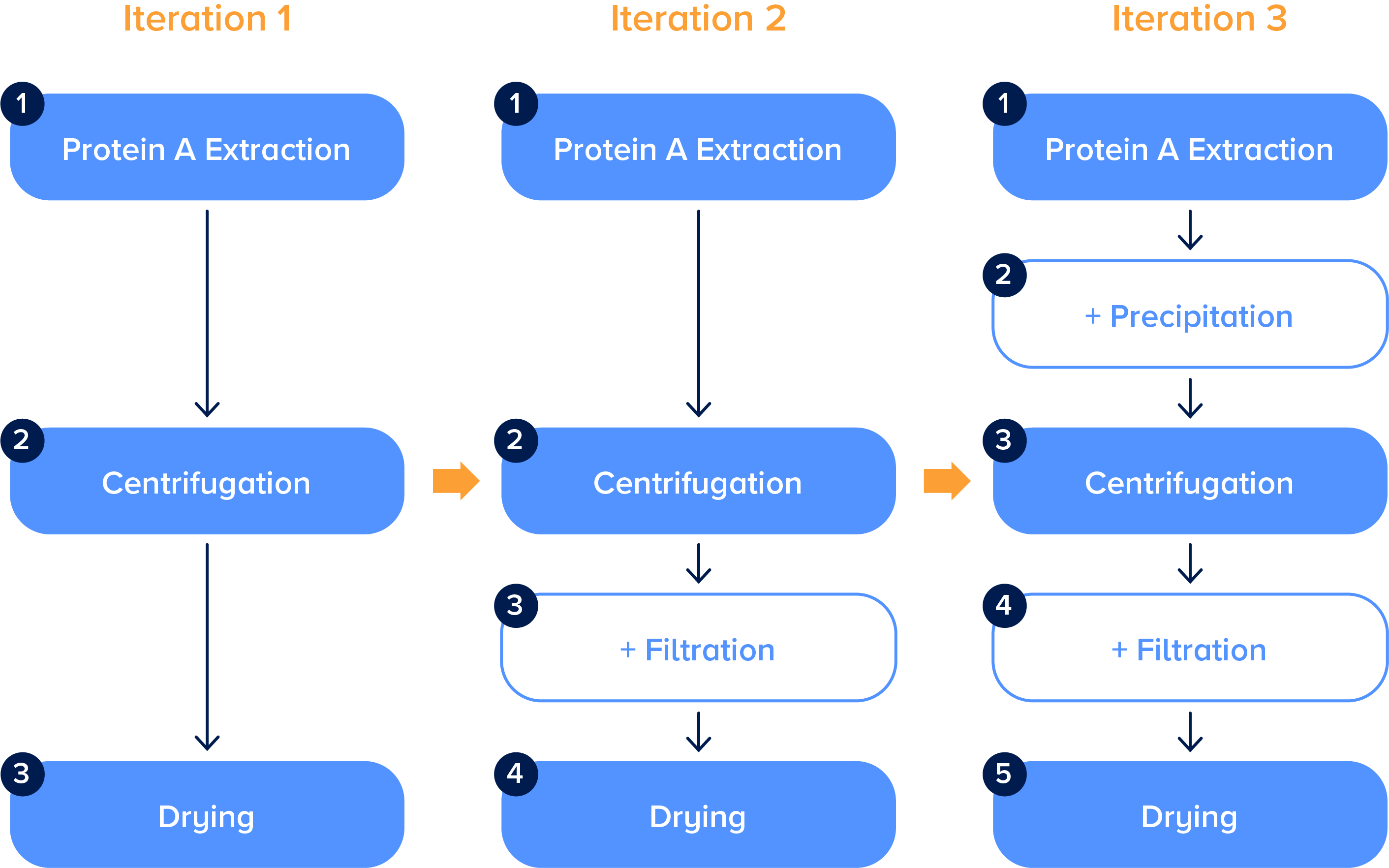
Modern life science workflows are complex and iterative. In this protein purification workflow, multiple versions need to be tested for scientists to optimize their outputs. To unlock new insights, scientists need flexible software that can adapt to process changes.
Companies that want to leverage advanced data science techniques need to digitalize their scientists’ work. Many companies have embarked on this journey but have had challenges with adoption and fragmentation of tools. At Benchling, we’ve worked with companies to consolidate many tools onto a single, unified platform. It models the complexity of large molecule R&D, is adaptable to changes in the scientific process, and provides tools that save scientists time in their day to day work. This all adds up to decreased coordination costs, increased data quality, and a shorter time between experimentation and analysis.
By structuring and centralizing your data on a flexible platform, you can unlock new capabilities
Laying this foundation with a suite of applications on a single platform allows companies to more easily layer on functionality like high throughput automation. High throughput automation is an important step as companies scale up their R&D, and running these experiments generates the kind of datasets that are useful for data scientists.
As a result, you can start running much more advanced and comprehensive analyses. Benchling’s rich application functionality sits on top of a platform that allows data to be accessed via our API and data warehouse. Your data scientists and engineers can write code that pulls unified data out of Benchling, integrates it with internal systems, and feeds data through analysis pipelines. Scientists can get recommended experimental conditions, managers can look across programs and determine where more resources are needed, and executives can flag programs that are promising or risky. Having put in place this foundation and having achieved this level of data analysis, our clients are already beginning to apply AI to their R&D efforts using data from Benchling.