Biotech’s Intro to Generative AI: Getting Started with LLMs
Summary: LLMs are ready for biotech today, and you don't need to be an ML shop to take advantage. This guide walks through how to get started, from choosing between build, buy, or open-source options to setting up your team and data strategy.
LLMs can accelerate R&D across the entire lifecycle, from hypothesis generation to manufacturing, not just drug discovery.
Build vs. buy vs. open-source each have real tradeoffs around cost, control, and data sensitivity, and most companies will end up using a mix.
Getting started isn't just about picking a model: you need a clear use case, clean data, domain experts involved early, and guardrails around IP and privacy.
“What is our AI strategy? How can biotechs use LLMs and ChatGPT today?”
These are the questions being asked at nearly every biotech company we work with. Biotechs want to know what advancements to expect with AI in the next six to twelve months. They want to know what they can be doing now to take advantage. And they need advice that’s specific to science.
For the first time in history, cutting edge, pre-trained machine learning models are available in no-code environments, making it easy for companies to adopt and benefit from AI. Simply put, you no longer need to be a machine learning shop to join the AI party. Large language models (LLMs) are ready for biotech today.
Biotech is a data-rich domain, which enabled a handful of flagship companies to gain ground with advanced machine learning and AI in the past approximately eight years. Recent triumphs with companies like Recursion, Nimbus Therapeutics, Generate Biomedicines, and Prescient Design demonstrate the accelerated timelines and better outcomes with custom ML models. Such progress required significant in-house data, time, and dedicated teams. Now, with LLMs, there are opportunities to accelerate biotech R&D without the same heavy-lifting of building customized models and pipelines from scratch. Plus, there’s parallel progress with “built for science” ML models that leverage similar architectures, such as AlphaFold, ESM, RFdiffusion, and MoFlow. All of this recent momentum with AI in biotech is causing even the most conservative and skeptical of scientists to pay attention.
In this guide, we're delivering wet lab scientists, IT, and biotech executives the information they need to get started on their AI strategy, beginning with LLMs that use natural language, like ChatGPT. LLMs like these are easier to deploy toward operational use cases, and can increase efficiency at every stage of the R&D process. We highlight problems that are well-suited for LLM technology throughout the entire R&D lifecycle, weigh pros and cons of build vs. buy vs. open-source, and shine light on how to build out your internal team and toolkit.
Generative AI, LLMs for the entire R&D lifecycle
Having the power of generative AI and LLMs at our fingertips has opened up a wide range of possibilities for researchers: generating hypotheses, extracting information from large datasets, detecting patterns, and simplifying literature searches — all via simply prompting a pre-trained model with natural language.
While much of the progress with AI has been about drug discovery, we’re underappreciating AI’s potential if we limit the focus here. There’s so much headroom for improvement across the entire lifecycle, from research to development, clinical trials, filing, and manufacturing. AI can reduce some of the hard work for scientists, the ‘daily grind’ of bench science. It can shrink the distance between the wet and dry labs. Companies that get this right will experience a compounding effect with AI, one that changes scientific output.
Here are some examples of how advanced ML models have been used throughout the R&D lifecycle, this includes both LLMs and other generative AI models.
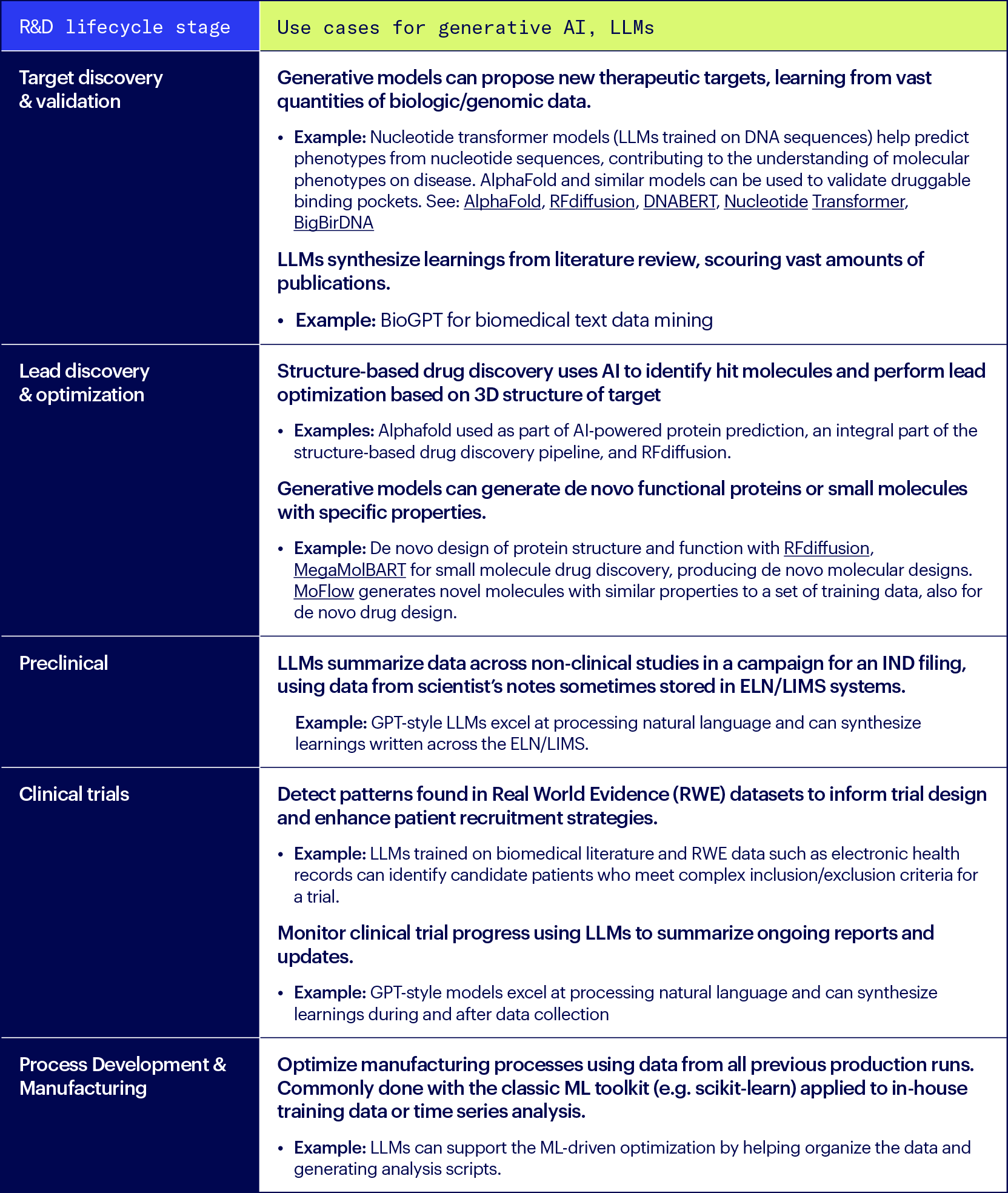
These examples are really just the beginning – the number of generative AI use cases in R&D grows daily. In addition, there are internal operational use cases that are helpful no matter where you are in the R&D lifecycle, these and are largely powered by LLMs:

Build vs. buy vs. open-source
One of the early considerations with LLMs is whether to build, buy, or use an open-source model. Note that these options are not mutually exclusive, and it’s likely that your company will benefit from implementing multiple options to serve different use cases.
Buy: Use a commercial LLM off-the-shelf
These are the most commonly used and accessible LLMs today. Usually you pay to use an API, rather than buying/hosting the model yourself.
Pros
Get started immediately. Can be as easy as opening your web browser (e.g. ChatGPT).
Minimal technical expertise and data needed. This also makes it very quick to evaluate whether it meets your needs.
Today’s best LLMs have great performance off-the-shelf, for many use cases.
Cons
Less control and visibility into the model and any fine-tuning you may need.
Can get expensive. You will most commonly pay to use the APIs.
Sensitive data handling is not trivial. You will need to set guidelines with your legal and security team on what data is safe to send, and how the third party will manage, store, and purge your data.
Examples: OpenAI’s ChatGPT, NVidia’s BioNEMO solution gives access to numerous state of the art models. Benchling also gives users access to Google Deepmind’s AlphaFold.
Build: Train an LLM yourself (or with help)
Due to prohibitive costs in data quantity, compute resources, and time, this is usually not the first step companies should take. While possible to keep costs down with non-internet-scale specific data, the investment, pros, and cons are no different from training any other kind of advanced ML in-house.
Pros
A model you build yourself is tailored to exactly what data you feed it, and you will have full control over every aspect of the model building, architecture, and performance. You also vet what you build.
Sensitive data is all handled within the team, no difficult contracts to negotiate.
If you already have an ML team doing advanced AI, they probably have the skill set and data to build/tune in-house LLM(s).
Cons
You will need a specialized team, and cleaned (or at least targeted) data.
Building an LLM can be cost-prohibitive, both in dollars and time.
Open-source: Use a pre-trained open-source LLM
Open-source LLMs are purpose-built for specific natural language (or biological sequence) processing, which can often be fine-tuned on datasets of interest.
Pros
You can still leverage the vast amount of training data the LLM was trained on, but are able to fine-tune on top of your own data.
Costs vary for access and use, with the good news that most do not require a paid license. Though the personnel costs can add up when you build out a dedicated team.
Full control over infrastructure and architecture.
Cons
Still requires a technical team and cleaned (or at least targeted) data to fine-tune.
Need to spin up infrastructure to use and productionize the LLM.
The open-source conversation models still lag behind commercially available LLMs on expert-like benchmarks, though this is quickly evolving.
Examples: Check out HuggingFace for a vast platform of source-available LLMs trained on a wide variety of data. Commercially available models range from generic NLP chat-based Llama2 to domain-specific biomedical models such as BioGPT. Remember to work with your legal team to understand the license agreement for each model to ensure it can be used as needed.
A fourth option — using a highly specific “traditional” ML model. Often, LLMs are overkill or simply less effective tools for what you need. LLMs, with their upwards of trillions of parameters, or “digital neurons,” can be overly complex black boxes. And remember the base models (without plugins) are optimized for language-related tasks. They do math poorly, compared to a simple calculator. Furthermore, if you are looking for interpretability and the ability to validate hypotheses, you still can’t beat statistical inference applied to well-designed experimental data e.g. with appropriate controls and sample sizes.
Getting set up for LLMs
Before diving into LLMs, invest time and resources into setting your team up for success. This includes prioritizing your use cases, building out the team, the culture, the guardrails for usage, and the plan for the text or data they might leverage.
1. Start with your specific use case(s)
Before jumping in, think deeply about your company’s domain capabilities and differentiated data assets. Are you trying to increase the probability and speed of finding your lead candidate, optimize production, or accelerate your operations? Do you even need an LLM for this particular case, or would other ML methods get you there?
The LLM should be trained on data that matches the task, and the exact ML or LLM approach will depend on the combination of your internal capabilities, data, and goals. Having your KPIs defined upfront will help your team select the right strategy and technologies, and help you evaluate and measure the impact and cost of your proposed method.
2. Invest in your data
A model will only be as good as the data it sees.
Decide what data is required to answer your specific question. Then decide, based on the quality, quantity, and sensitivity of the data input, what model implementations are doable, and if that meets your goals.
For most scientific use cases, curating, cleaning, and processing the data will take a bulk of time, and in particular defining the input and output examples to help with few-shot learning will really increase the performance of your model. For operational use cases, you have a bit more leeway with unstructured data, but the fact remains: garbage in -> garbage out. Use LLMs as the “carrot” to get your users to give you quality data.
3. Bring in your domain experts early
LLMs are powerful mathematical tools, not magic. What makes them special is that you can interface with them without code. This does not mean they can read your mind, so giving ample context, some examples to learn from, and clear instructions can be the difference between something unintelligible or made up vs. a clear answer with references.
When results can’t be verified and stakes are high, the risk of an LLM to “hallucinate” or simply return something false can seem like a deal-breaker. However, the quality of a response is often directly related to the quality of the prompt. Explicitly asking for verifiable references and stating in the instructions to avoid high-uncertainty answers can reduce the probability of this happening by quite a lot. And, as always, get an expert to validate the outputs and assess the limitations of the system.
But more effectively, getting the expert to set up the prompt with examples and be involved in the actual prompt engineering will reduce the probability of failure.
4. Be proactive on ethical, intellectual property (IP), and privacy implications
The use of LLMs is new territory rife with a complex web of ethical, IP, and privacy implications. We frequently encounter concerns like, “Does engaging with ChatGPT on a proprietary project inadvertently expose our IP or breach our privacy standards?”
It’s important to address these issues head on and take a proactive approach. Cross-functional leadership — involving the Legal and IT — is key. This collaborative effort should holistically assess potential risks, based on your company’s specific use case(s), and generate guidelines and requirements for the responsible, legal, and ethical use of LLMs within your organization.
5. Focus on team and culture
For AI in R&D to work, it requires bringing together teams of engineers, data scientists, and scientists. Granted when working with pre-trained LLMs, it removes the need for ML engineering. However, you do still need the team to be taking on data science-adjacent work, especially to validate and understand the limitations of the models and the underlying data. To work with open-source LLMs, you need machine learning engineers who can understand the complex data types being produced, who can fine-tune and work with weights, and who can collaborate with scientists about the insights they want to extract.
On the operational front, virtually every company can start leveraging this technology for generic productivity gains starting today. Beyond the scientific AI team, it’s important to foster a company-wide understanding and acceptance that the technology is here to stay, set guidelines on usage, and encourage smart experimentation. Make ChatGPT readily available, and provide training and clear guidelines on how to use it safely and effectively. In addition, provide clear expectations on how the data your users input directly affects the quality of model outputs. Your competitors have the same tools available, so it’s all about who gets the most efficiency gains in the long run.
You are preparing for a future where both ML and AI will be critical to your business. Operational use cases for LLMs and pre-trained models may be more intuitive and require less expertise in ML to get started, but do not replace the ML and scientific expertise required to build an in-house team and data strategy to support the scientific use cases. You will need both to succeed.
Don't get left behind
The design-test-build-learn cycle is here to stay. But how we operate in each phase is dramatically transforming with AI. It’s not just about productivity gains. These technologies encourage a level of interdisciplinary experimentation and creativity. They allow people to be bold, and test new hypotheses with less risk.
Embracing technology early has provided companies with a crucial competitive advantage, time and time again. By now, the cloud is so essential, it’s hard to think of modern business and even daily life without it. A business that didn’t switch from fax machines to computers would be left behind. Yes, the world of LLMs can feel fast and hyped up, and it’s true that these technologies are not perfect or polished quite yet. But with the pace of innovation in AI, the growing pains will be short-lived. Harnessing this technology for real-world biological breakthroughs, whether that’s life-saving drugs, more sustainable crops, or safer consumer goods, is the AI impact that matters.
Key definitions
Generative AI: A type of artificial intelligence that has the capability to create text, images, and other forms of media by employing generative models. These models grasp the intricate patterns and structures found within the data they are trained on, allowing them to generate fresh data that exhibits similar attributes. Recent advancements in transformer-based deep neural networks brought forth generative AI systems with a unique ability to respond to natural language prompts. Among these are expansive language model chatbots like ChatGPT, Bing Chat, Bard, and LLaMA.
Large Language Models (LLMs): This is a type of generative model trained on massive (internet-scale) quantities of data, and serves as a foundation for generating human-like text based on the input it receives. While they are usually trained on natural language, these models can also be trained on vast amounts of biological sequence data (DNA/RNA/proteins), and then used to generate new sequences that would have high probability according to the training data.
Tokens: The fundamental “vocabulary” for an LLM to process and generate language or sequence data. Both input/output will be broken down into tokens, and it is the sequence of tokens that is transformed into meaning. LLMs have a “token limit” based on computational and memory limits, and this will determine how much information your LLM can process and keep in-context at one time.
Prompting: The initial input that instructs a natural language model to generate text in a particular way. Using LLMs effectively usually takes some trial and error with prompt engineering, a process to refine prompts to produce the desired model output.
Fine-tuning: Adjusting and adapting a pre-trained foundation model to perform specific tasks or to cater to a particular domain more effectively. Applies to both natural language models and biological sequence models.
Learn more about AI at Benchling.
Download our guide on AI for biotech
Read more on getting started with LLMs in our guide to generative AI for biotech.


