Product sheet
Model molecules such as proteins, bio-conjugates, small molecules, and nucleotides with customized metadata fields. Configure entity and data types with a simple, point-and-click interface.
Map relationships across DNA, plasmids, cell lines, proteins, and more. Record molecular lineage and apply uniqueness rules to prevent duplicate registrations and manage resources.
Connect samples, notebook entries, and results directly to their corresponding molecules for a complete, 360° view. Collaborate easily with complete, high-quality, F.A.I.R. data.
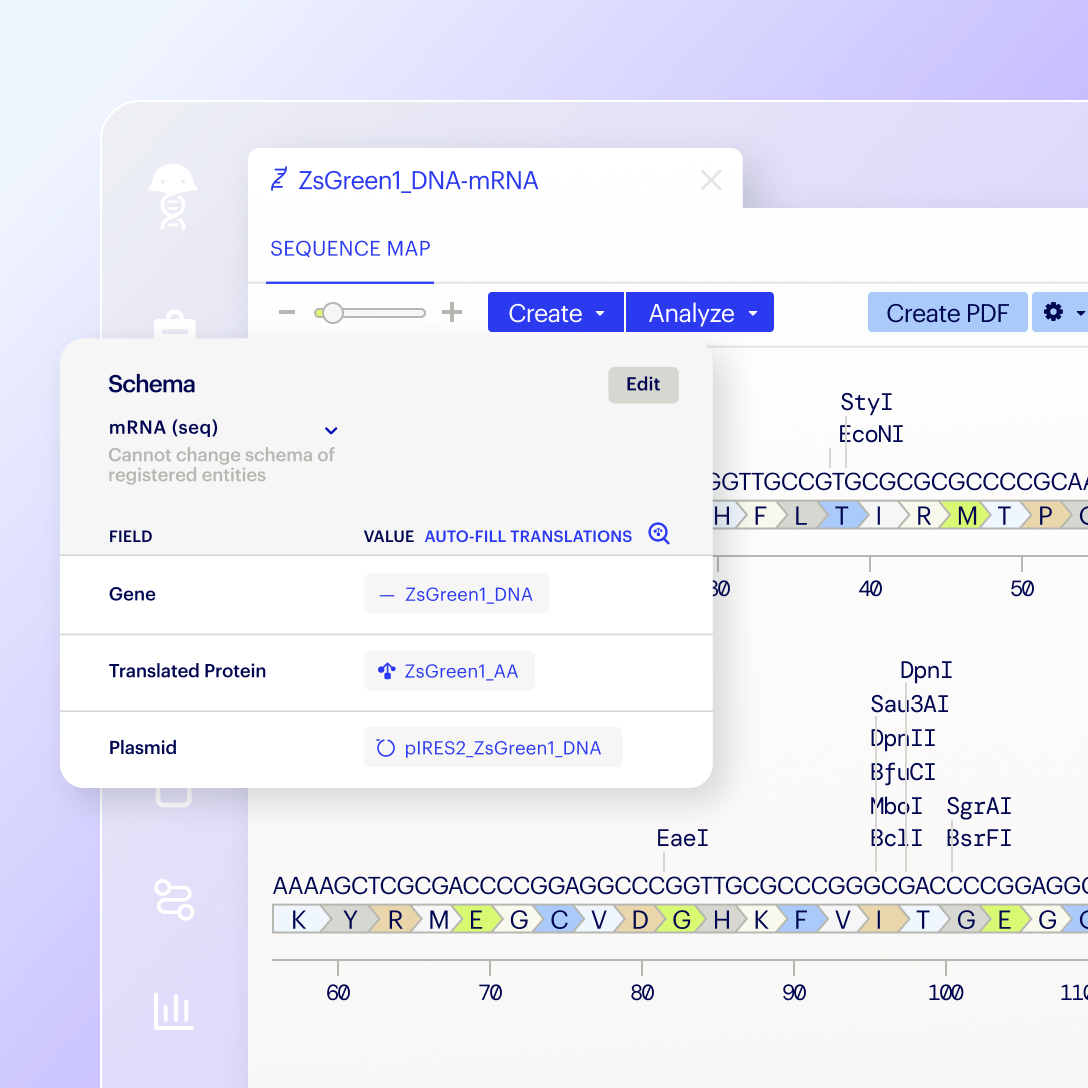
Model biomolecules, small molecules, and derivative combinations like bio-conjugates and chemically-modified biomolecules
Map relationships between registered entities, such as parent–child relationships between entities and their batches or aliquots
Enforce uniqueness constraints based on sequence or chemical structure composition
Automatically detect and link reused component sequences, such as expression cassettes in plasmid sequences
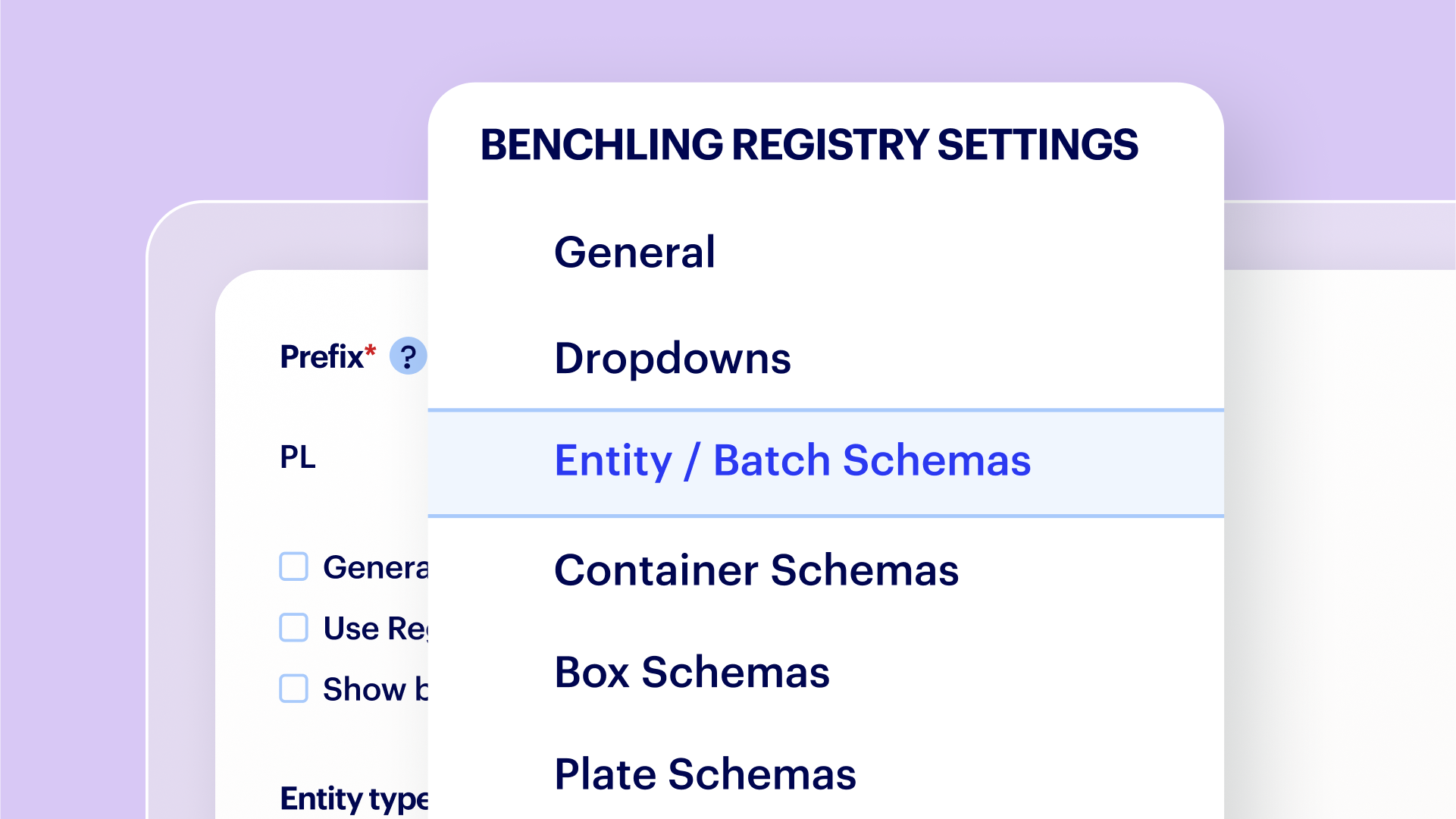
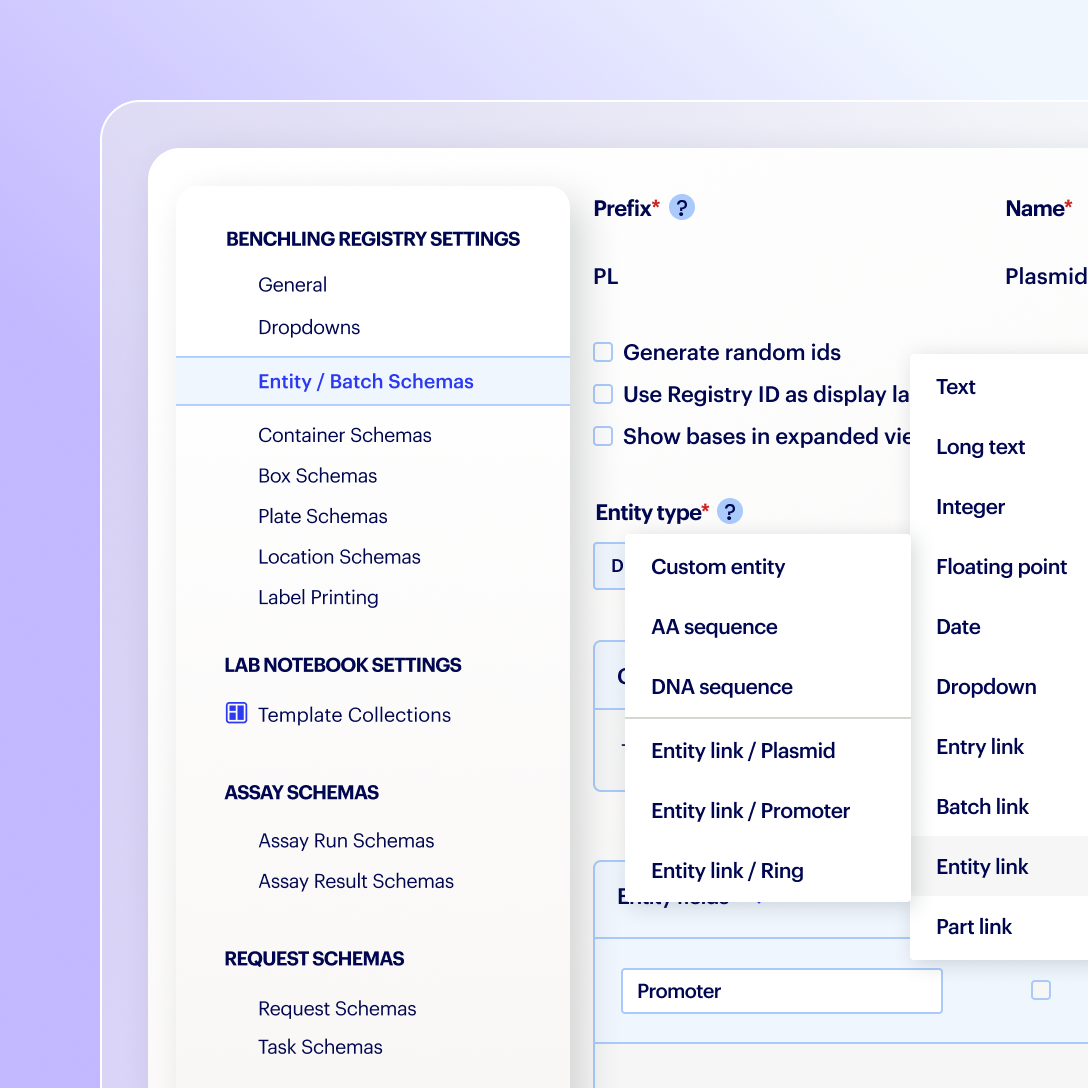
Assign admin privileges to manage configurations with a simple point-and-click interface
Configure a range of data types and entities, including DNA, RNA, chemically-modified sequences, proteins, antibodies, small molecules, bioconjugates, and animals
Add custom fields, metadata and formulation schemas for complex mixtures and reagents
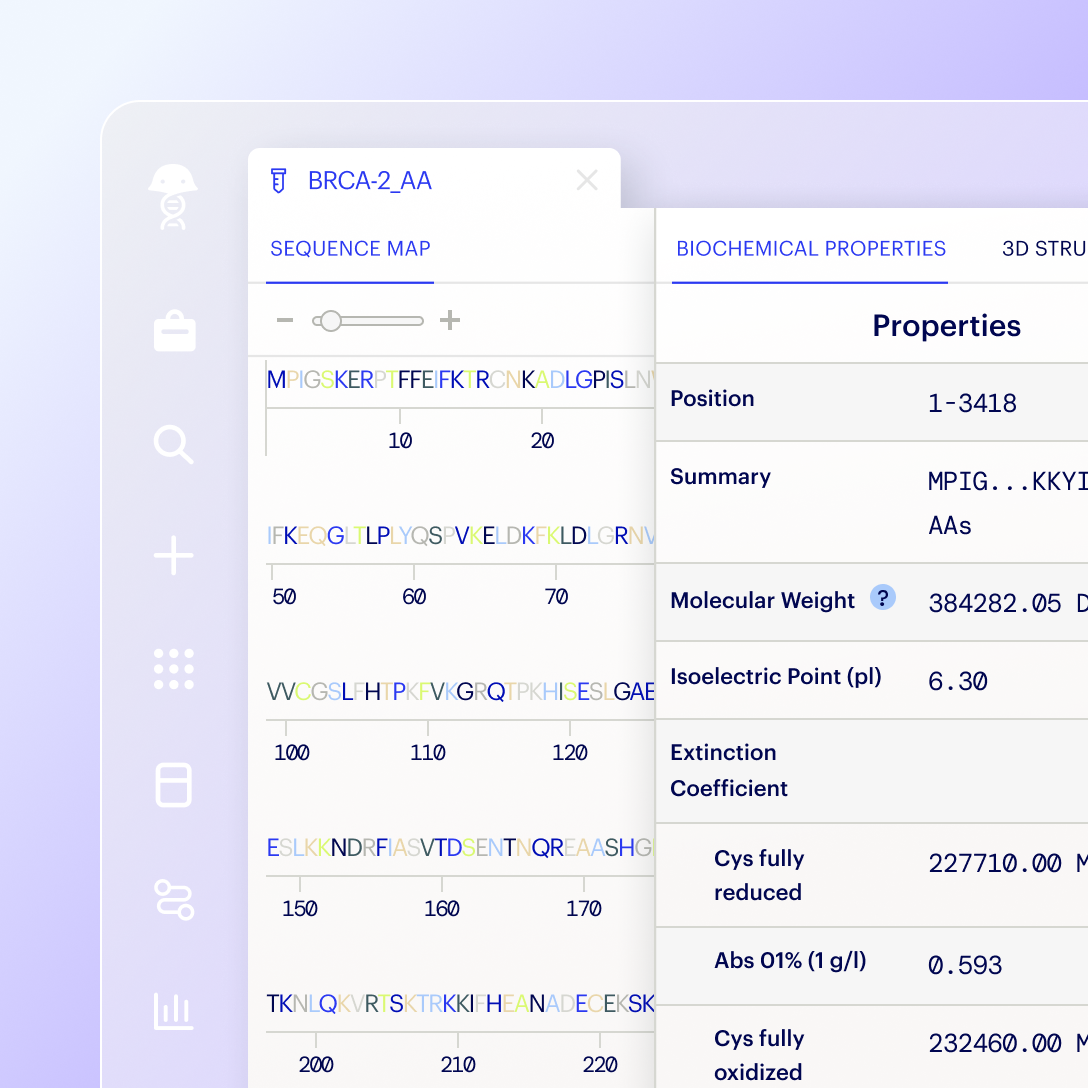
Auto-compute metadata from linked entities, including physico-chemical properties like weight, isoelectric point, Log P, TPSA
Automatically bulk-register entities from cloning, translation, or imports via spreadsheet or APIs
Find entities by field, ID, or aliases, and see every Notebook entry where they appear
Search large molecules by partial sequences and search chemical structures by substructures or similarity
Benchling gives transparency across the company. Because everything is in one place, our scientists don't have to jump from system to system. They can quickly get all the details and all the data associated with any construct or experiment.
Vice President of Discovery, Obsidian