The difference between purpose-built R&D agents and enterprise AI assistants

A question R&D teams are asking more often: "We already have access to an enterprise AI assistant through our company agreement. We can connect it to Benchling via MCP. Why do we need Benchling AI agents?"
Enterprise AI assistants have broad context across biology, chemistry, and drug discovery. For general scientific questions, literature synthesis, and communication tasks, that breadth is useful. But broad context is a different thing from knowing your science.
What your enterprise AI assistant can't access is the scientific record your R&D organization has built in Benchling: the experimental plan, what was actually done, the result, and what the team decided to do next. That complete trace, from hypothesis to outcome, linked across sequences, batches, assay runs, notebook entries, and workflows, is what makes R&D data useful to an AI. It lives in Benchling, structured and connected in ways that a text export can't preserve.
The problem: R&D knowledge is trapped
R&D organizations generate a lot of data. A single drug program can produce thousands of experiments, hundreds of assay runs, and structured result tables that accumulate over years. That data has real value, not just as a record of what happened, but as context for what to do next.
The problem is that most of it is hard to access quickly. When a scientist needs to answer a question like "What's the best-performing construct from our Q3 CRISPR screen, and how does it compare to what we tried in 2022?" they often still do it manually. They search, they scroll, they ping a colleague, they export to Excel. The answer is usually there somewhere. Getting to it takes longer than it should.
The consequences compound: scientists re-run experiments that already happened, cross-experiment questions that should take an hour take a week, and institutional knowledge walks out the door when team members leave.
What R&D teams need from AI goes beyond faster search. They need to synthesize results across experiments, surface anomalies in assay data, support hypothesis generation, and reduce documentation burden, without leaving the environment where their science already lives.
Three gaps enterprise AI assistants can't close
When R&D teams try to address these needs with an enterprise AI assistant, they run into the same three limitations:
Context. An enterprise AI assistant has no understanding of your organization's data model. It doesn't know that your "Result" field in Assay Schema X maps to a specific numeric threshold your team defined, or that Batch ID 2047 is downstream of a registry entry with a known quality flag. Without that context, answers are generic at best and misleading at worst.
Connectivity. Enterprise AI assistants operate only on what you give them. They work on snapshots of data that was copied, pasted, or exported, not on the live, structured environment where science actually lives. Building more comprehensive integrations is possible, but at considerable effort to build and maintain.
Credibility. Scientists need to know where an answer came from, which records it's based on, and how to verify it. Enterprise AI assistants produce outputs with no native links back to source data. In a GxP environment, that's not just a usability problem. It's a compliance risk.
These gaps aren't solved by using a smarter model. They're solved by building AI that understands the data model from the start.
What Benchling AI Agents are actually built to do
Benchling AI is built on a purpose-built agent harness tuned specifically for scientific workflows. Like any agent, it uses LLMs to reason and generate responses. What surrounds it is what matters: a scientific context layer that understands Benchling's data model, tooling that knows how to query structured and unstructured R&D data, and an orchestration system that plans and evaluates multi-step tasks before returning a response.
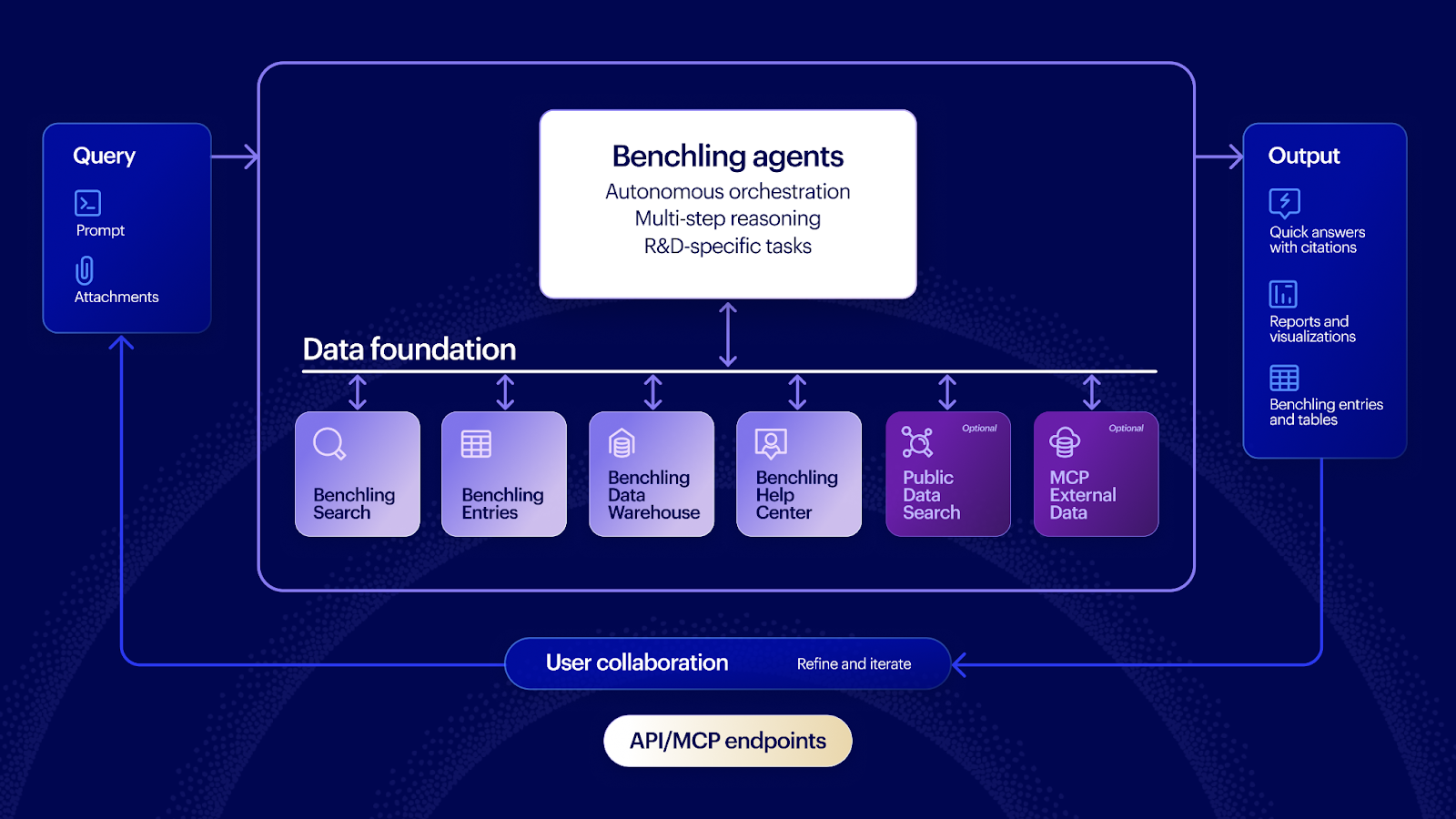
A few things that make Benchling agents different in practice:
They reason across structured R&D data, not just documents. Both enterprise AI assistants and Benchling AI agents can read notebook entries and produce text summaries. Benchling agents can also query the underlying structured data those entries are connected to. Ask a Benchling agent about an assay and it can read the notebook entry describing it, query the assay schema directly, filter by result threshold, join across batches, and surface the top candidates, all in a single response. An enterprise AI assistant working from an export can only do the first part.
They're multi-model by design. Benchling doesn't use a single LLM for all tasks. Different models have different strengths, and those strengths aren't evenly distributed. By selecting the model that performs best at each subtask based on internal evaluation, Benchling agents can outperform what any single model would deliver on its own.
They return deep-linked results. When Ask or Deep Research returns a response, it contains direct links to the specific entities, entries, registry items, and results it referenced. A scientist can click directly into any cited object to explore and verify the answer, right within the same panel of their Benchling interface. When a scientist uses an enterprise AI assistant instead, that proximity disappears and the friction the AI was supposed to eliminate comes back.
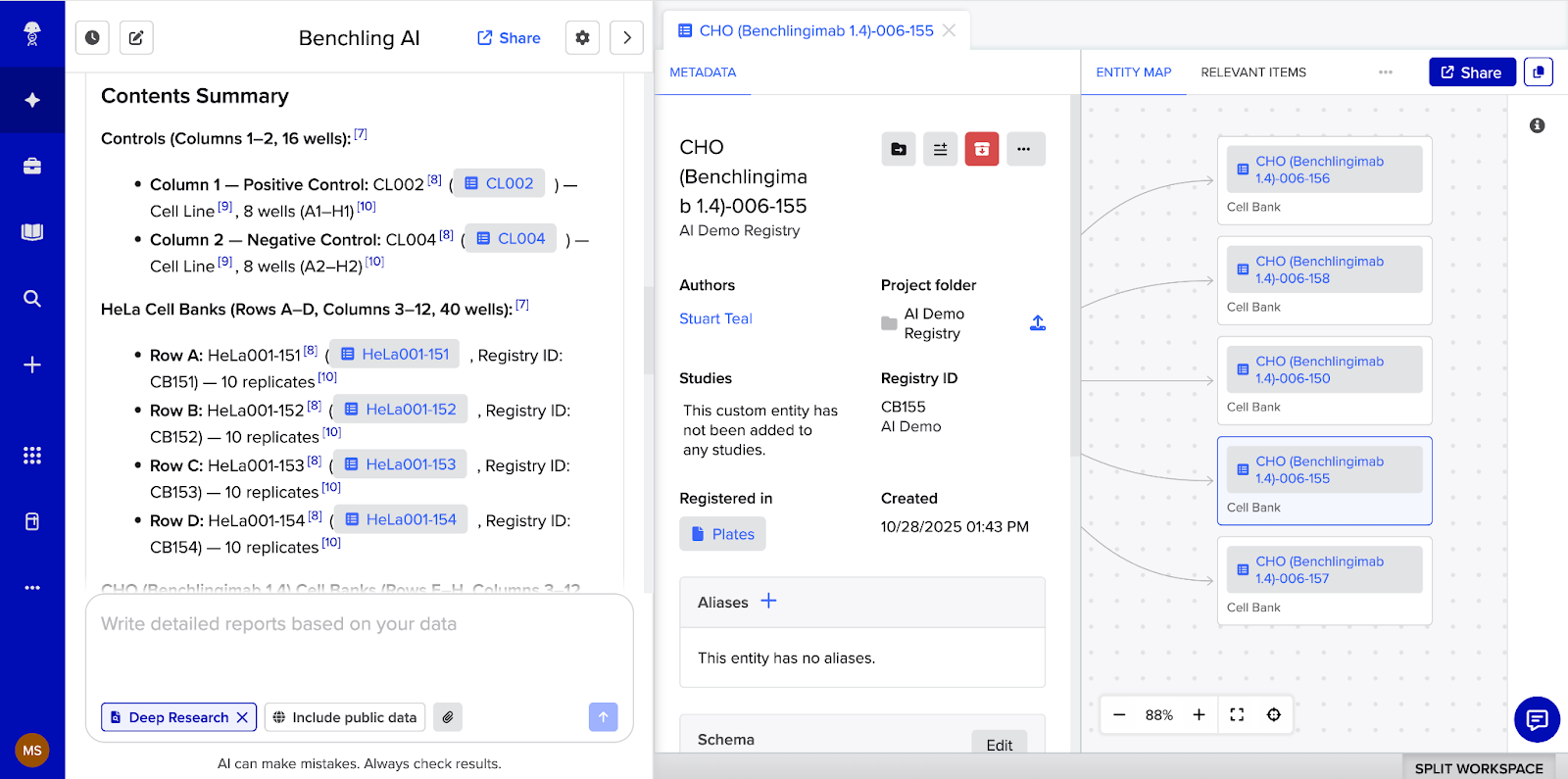
Compose creates Benchling objects, not text. When Compose generates an experiment plan or populates a data table, it doesn't produce text for the scientist to copy and paste. It creates actual Benchling objects, notebook entries, templates, structured tables, populated directly within the platform with full audit trails intact. The scientist reviews and confirms the output before it becomes part of the organization's data environment.
What actually happens when an enterprise AI assistant connects via MCP
When a customer connects an enterprise AI assistant to Benchling via our MCP Server, it is not making raw API calls and passing results to a general model. Our MCP Server calls our Deep Research and Ask agents behind the scenes, with the same dedicated prompts, the same agent harness, and the same scientific tuning.
Customers using an enterprise AI assistant with Benchling's MCP Server are already using Benchling's agent intelligence. The real distinction is between using those agents in-platform versus calling them externally, where deep linking, navigation, and object creation are reduced.
On cost: many teams assume the MCP path is cheaper than using Benchling AI directly. It isn't. Credit consumption is the same either way. The cost conversation should focus on value and quality of outcomes, not on the assumption that going through an external AI assistant is the more cost-efficient option.
Open by design
If Benchling AI agents are purpose-built for the Benchling data model, does that mean customers are locked in? No.
Benchling's MCP Server lets any MCP-compatible AI tool query Benchling data as part of a broader workflow. The MCP Client works in the other direction, letting scientists pull data from external tools directly into Deep Research without leaving Benchling. Open APIs across entities, assays, entries, inventory, and workflows mean customers can route their data to any downstream system or AI tool they choose. Learn more about how Benchling AI connects to your R&D stack.
The bottom line
Enterprise AI assistants are useful for literature review, communication drafting, and broad scientific Q&A. But where scientists need to query their data, synthesize results across experiments, and create artifacts that become part of the scientific record, the fit breaks down.
Benchling agents are built specifically for that navigation. They use named entity recognition to understand scientific terminology in context, supervisor prompts tuned for R&D workflows, and explicit citations tied back to the source records they queried. These are the specific mechanisms that let scientists verify an answer, trace it back to its source, and use it with confidence in regulated environments.
Want the full technical breakdown? Read the full white paper.
Ready to see Benchling AI agents in action? Contact your account team or visit benchling.com/ai.



