AI read 200 million papers, but still missed your last experiment
Introducing Hypothesis Generation with web search on Benchling AI, grounded in your internal data and the published literature AI can generate hypotheses, but are those hypotheses worth testing?
For the past few years, the standard AI scientist demo has started with literature review: read the papers, connect the findings, propose a hypothesis. It’s powerful, but the model only gets a fraction of the scientific context it needs.
Point most AI tools at the published literature and you get roughly the same conclusions because a hypothesis generated from public data alone is a consensus hypothesis. Valuable hypotheses come from combining public data with data no model was trained on: your experiments, your assays that failed, and your program decisions.
Today we’re introducing Hypothesis Generation with web search on Benchling AI. Together, they reason across your institutional memory and the published literature, turning hypothesis generation from a literature exercise into a program-specific starting point for your next experiment.
Good hypotheses are more important than many hypotheses
I have some history here. Earlier in my career I worked on the target identification platform at BenevolentAI. Despite being an early player in this space, the premise is very similar to what you still hear today: the biomedical literature is too vast for any human to read, so mine it at scale and the connections everyone else missed will fall out. To do this, we spent years building a knowledge graph over public data and training AI models on top to discover novel targets.
We surfaced a lot of novel targets. So many novel targets, in fact, that we had to build an additional layer of tooling to help our scientists sift through all of them. And even then, with all of the investment in our technology, we found that basing our models solely on public data was insufficient. We eventually built out our own labs to generate proprietary data.
The technology wasn’t the problem. It was the data.
Public data can only go so far
Every connection a model finds in the published record is latent in a corpus that thousands of other scientists and models are already reading. The literature is also structurally incomplete. Positive results get published far more often than negative ones. Research directions that have already been tried — but deemed unfruitful — are almost never published. A model reasoning over all of this inherits those gaps.
Ask a general-purpose chatbot for a hypothesis and you get a competent guess from something that has read everything and knows nothing about your program. Ask a smart new hire on day one and you get the same. Neither is what you want.
A hypothesis worth running is novel, specific, testable, and relevant to your exact scientific goal, not just to biology in general. What you need is an AI Scientist that can generate high quality hypotheses based on your science.
Why we’re different
Benchling has spent more than a decade building a platform to capture and structure scientific data. Benchling AI is being used by thousands of scientists to design new experiments directly in their notebook. We’ve now connected that institutional memory to the published scientific record so that Benchling AI will reason over both at the same time. By leveraging web search on AWS Bedrock AgentCore, Benchling AI can combine internal and public data securely.
Hypothesis Generation on Benchling starts from your unique data, then reasons over public literature to suggest new ideas. Get the right context in front of the model before it reasons, and the output changes from a mediocre guess into a high quality hypothesis. It’s like hiring the same smart new hire, except this time, this one has already spent years inside your organization.
Multiple models for better performance
Getting the right data in front of the model is necessary. But even with perfect context, a single model has blind spots. That's why Hypothesis Generation in Benchling AI runs several models from different providers in parallel to get better results.
To generate hypotheses you'll actually use in the lab, you need to push the limits of what today's AI can do. Ask an LLM the same question twice and you get variations on one point of view. Run several models from different providers and you'll get significantly better results.
OpenRouter recently benchmarked this: on a hard deep-research benchmark, a fused panel of models beat every individual frontier model, and a panel of cheaper models came within a point of the best single model at half the cost.
I haven’t changed my mind about the hard part
Hypothesis generation is just the start of the scientific process.
The hard part is what comes after: translating a hypothesis into an experiment design that can actually test it, running the experiment in the physical world, importing data that's messier than any AI predicted, and analyzing data that doesn't match what you expected. That's where programs fail and where AI tools that live only in the literature break down.
All of this is part of the AI Scientist we’re building where we’re not just generating ideas, but also carrying out experiments to validate them.
Try it
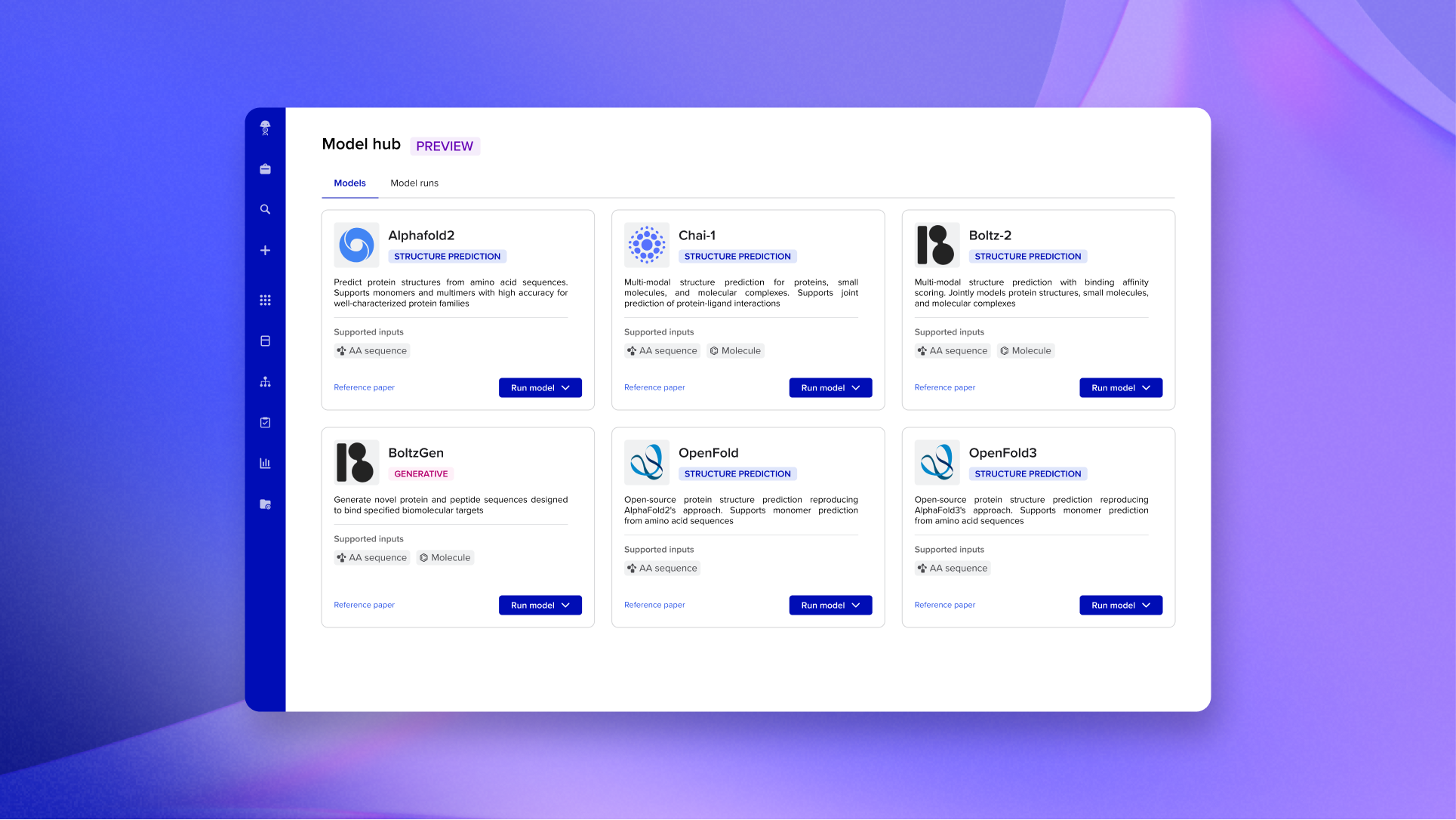
If you're a Benchling customer, Hypothesis Generation with web search is available today. Open Benchling AI, ask it about a target,mechanism, or troubleshooting problem you're actively working on, and watch what it does with your data and the literature together.
If you're not a customer yet, request a demo and we’d love to show you more.